Now that we know about proc, lets implement the Caesar cipher again,
this time with an arbitrary alphabet.
First, we define a global variable Alphabet that lists all the
characters we intend to encode. Note that, in this case, the newline
character is in our alphabet, as well as a space and a few punctuation
characters.
> Alphabet := `ABCDEFGHIJKLMNOPQRSTUVWXYZ
abcdefghijklmnopqrstuvwxyz., `;
![]()
Now, we can define two procedures, ToNum and FromNum,
which convert character strings to and from lists of numbers. The
numbers correspond to the position of the character in
Alphabet, with (in this case) A=0. As in Scramble
of §2.1, we use substring to pick out
the i-th character, and SearchText to find its position in
Alphabet. Note that Alphabet is declared as a global
variable.
> ToNum := proc(text)
local i;
global Alphabet;
[seq(SearchText( substring(text,i),Alphabet)-1, i=1..length(text))];
end:
FromNum := proc(numlist)
local i;
global Alphabet;
cat(seq( substring(Alphabet,numlist[i]+1), i=1..nops(numlist)));
end:
Now the Caesar cipher is written in terms of these functions. Note that this is a little easier to understand than the previous version.
> Caesar2:= proc(plaintext, shift)
local textnum,codenum,i,p;
global Alphabet;
p := length(Alphabet);
textnum := ToNum(plaintext);
codenum := [seq( modp(textnum[i]+shift, p),
i=1..length(plaintext)) ];
FromNum(codenum);
end:
It works as follows.
plaintext message, and a shift amount.
The temporary variables that we will use during the conversion
process are declared as local, and the Alphabet is
declared as global.
p.
textnum.
textnum is shifted, and the result is
taken
mod p. Note that since ToNum yields
result in
{0, 1,..., p - 1}, we don't have to monkey
around to get the result into the proper range like we did in
the first Caesar (§2.2,
p. modp(a,p) to compute
a mod p, instead of writing
a mod p as before. Either way works fine.
Let's see how it works.
> Caesar2(`Veni, Vidi, Vici`,3);
![]()
> test:=`I have heard the mermaids singing, each to each
I do not think that they will sing to me.`;
![]()
> encoded:=Caesar2(test,38);
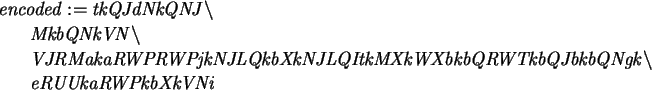
Note that since our alphabet treats an end-of-line as a character, the linebreaks in both the plain and encoded versions are significant, and are different in number. We can use the same function to decode, but giving the negative of the shift as the key.
> Caesar2(encoded,-38);
![]()
Finally, notice what happens if we try to encode characters that do not occur in our alphabet. To better see what happens, we will shorten the alphabet dramatically.
> Alphabet:=`abcdefghijklmop_`;
![]()
Now let's re-encode the test message, with a shift of zero. Ordinarily, a shift by 0 would not change the text at all. But with the shortened alphabet, something happens to the characters that aren't mentioned.
> Caesar2(test,0);
![]()
Can you explain why this happens?